In machine learning, the validation of binary classifiers, algorithms that categorise data into two classes, is essential. However, a frequently overlooked issue is prevalence shift, which occurs when two test datasets have different rates of positive instances. This phenomenon can distort performance metrics, leading to incorrect model evaluations.
Understanding the problem
Prevalence shift fundamentally affects the interpretation of metrics used to validate binary classifiers. Without accounting for it, researchers risk inaccurate conclusions about model performance and study on the utility and discriminative power between metrics performances. For example, while metrics like Matthews’ Correlation Coefficient (MCC) are often promoted as superior to accuracy or Cohen’s kappa and robust to imbalanced test datasets, these claims can be flawed if prevalence shifts are ignored.
This issue is particularly relevant in Quantitative Structure-Activity Relationship (QSAR) modelling, a key tool in drug discovery and toxicology. (Q)SAR models predict biological activity based on chemical structure, requiring accurate validation to ensure reliable real-world applications. Prevalence shifts in (Q)SAR datasets, due to varying conditions or sources, can lead to misinterpretation of safety or efficacy data, with significant implications for drug development and environmental assessment.
The role of prevalence in metrics
Firstly, prevalence is a characteristic of the dataset, not the model itself, and influences most performance metrics except sensitivity and specificity. And secondly, using the confusion matrix, which fully characterises the performance of a model against a test set, and the definition of sensitivity and specificity it can be demonstrated that the four types of predictions—true positives, true negatives, false positives, and false negatives, depend on either sensitivity or specificity, prevalence, and the total dataset size (N). For example:
![]()
Therefore, the metrics sensitivity and specificity fully characterise model performance and performance metrics depend on prevalence. This prevalence dependence means that metrics like MCC cannot be compared directly across datasets with differing prevalence, as such comparisons can misrepresent model performance.
A solution: Calibrated/Balanced metrics
To address this, Lhasa Senior Cheminformatician, Sébastien Guesné et al. redefined balanced accuracy as the metric accuracy calibrated for a prevalence of 50% instead of the traditional average of sensitivity and specificity. The balanced version adjusts the metric to be prevalence-independent, enabling fairer comparisons. This novel definition can also be applied to other performance metrics, resulting in “calibrated” or “balanced” versions that provide more robust model validation. For example, balanced MCC:
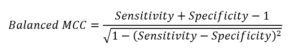
This work was presented at the Ninth Joint Sheffield Conference in Chemoinformatics in June 2023 and is published in the prestigious Journal of Cheminformatics, titled “Mind your prevalence!”.
By adopting calibrated/balanced metrics, researchers can ensure reliable evaluations of binary classifiers even under prevalence shifts. This approach strengthens the credibility of machine learning models, particularly in critical fields like (Q)SAR, where accurate validation underpins chemical safety decisions with real-world consequences.
Mind your prevalence
Prevalence and prevalence shifts are not minor details but crucial factors in the validation of machine learning models. Performance metrics must be considered as complementary tools, with each providing unique insights. The work of Guesné et al. highlights the importance of reporting and addressing the prevalence and/or prevalence shifts to ensure robust and reliable model evaluations.
For further details, explore the full open access publication by Guesné et al. here.
Last Updated on February 3, 2025 by lhasalimited


